


Next: Structure of Standard Charm++
Up: Parallel Implementation using Charm++
Previous: Mesh Partitioning
Contents
A good representation of the efficiency of the parallel
solution is to observe the parallel speedup of the code, given by
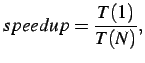 |
(2.35) |
where 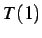 is the time required to run the simulation on one processor,
and
is the time required to run the simulation on one processor,
and 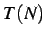 is the time required to run this same simulation on
is the time required to run this same simulation on 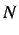 processors. With this we can track how well the code is able to perform
when distributed across multiple processors. Ideally, we would prefer
to have perfect speedup, where the solution time
is decreased in proportion to the number of processors. Unfortunately,
the speedup of most simulations begins to decrease with an increasing
number of processors. This is because the cost of the parallelization
becomes greater relative to the cost of the computations performed
by each processor. Eventually, for many processors, the communication
between them dominates the total time of the solution.
processors. With this we can track how well the code is able to perform
when distributed across multiple processors. Ideally, we would prefer
to have perfect speedup, where the solution time
is decreased in proportion to the number of processors. Unfortunately,
the speedup of most simulations begins to decrease with an increasing
number of processors. This is because the cost of the parallelization
becomes greater relative to the cost of the computations performed
by each processor. Eventually, for many processors, the communication
between them dominates the total time of the solution.
Mariusz Zaczek
2002-10-13