


Next: Parallel Structure of the
Up: Parallel Implementation using Charm++
Previous: Computational Efficiency
Contents
A standard serial FEM code is parallelized with the Charm++
FEM framework by distributing it into four main subroutines:
init, driver, mesh_update and finalize.
This framework has been developed especially for parallelization
of finite element codes. Although the original must be distributed
across the four main subroutines, it still maintains the basic
serial form.
The init routine starts the code by reading the global mesh
and associated data, flags and connectivities for the nodes and
elements. The program can have many different element types, such
as cohesive or volumetric elements, but only a single node type.
The node data are packaged using the following calls:
where FEM_Set_Node() sets the number of total nodes in the
system with #ofnodes and the number of data doubles for
each node using #ofdatadoubles. A data double is equal to 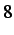 bytes in 32-bit systems, which is equivalent to one REAL*8 or
two INTEGER types.
The second call, Fem_Set_Node_Data_r() sends the array of nodal information
to the driver routine. The size of each individual element
of this array is equal to the total number of data doubles specified
by the previous call. It should be noted that all data be in full
bytes. This is already satisfied if the data elements are of
type REAL*8, but if the any data is of type INTEGER we must
have INTEGER pairs.
bytes in 32-bit systems, which is equivalent to one REAL*8 or
two INTEGER types.
The second call, Fem_Set_Node_Data_r() sends the array of nodal information
to the driver routine. The size of each individual element
of this array is equal to the total number of data doubles specified
by the previous call. It should be noted that all data be in full
bytes. This is already satisfied if the data elements are of
type REAL*8, but if the any data is of type INTEGER we must
have INTEGER pairs.
The element data and connectivities are passed using the calls
where FEM_Set_Elem() sets the element type, the number of
elements of this type, the number data doubles per element and the number
of connectivity doubles per element. The element type is an integer number
which is typically 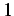 for cohesive elements and
for cohesive elements and 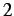 for volumetric elements.
The element data and connectivity are stored in similar fashion to the
nodal data although they are broken across two separate arrays. This is
because the partitioning will only use the connectivity information
to determine the proper distribution across chunks and so the data is
not needed at this time. The element data and connectivities are passed
on to driver using the FEM_Set_Elem_Data_R()
and FEM_Set_Elem_Conn_R() calls, respectively.
for volumetric elements.
The element data and connectivity are stored in similar fashion to the
nodal data although they are broken across two separate arrays. This is
because the partitioning will only use the connectivity information
to determine the proper distribution across chunks and so the data is
not needed at this time. The element data and connectivities are passed
on to driver using the FEM_Set_Elem_Data_R()
and FEM_Set_Elem_Conn_R() calls, respectively.
Once fully packaged, the data is sent on to Charm++ which uses the
Metis program to partition the mesh into several chunks. These
chunks are then passed on to the processors used in the simulation.
Unlike MPI, which limits only one chunk per processor, Charm++
assigns several chunks per processor which enables it to dynamically
load balance a simulation by simply migrating the small chunks to less
active processors, as necessary.
The driver routine is then called on each chunk, where it performs the
various calculations and data manipulations. The node and element
data and connectivities are received by driver using the following
calls, which are the mirror images of the data "send" calls, FEM_Set(),
initiated by the init routine:
where the parameters are the same as those defined for the FEM_Set_
calls.
During each driver call the CVFE scheme is applied to the nodes
and elements of the particular chunk. Unfortunately, the boundary nodes
require special treatment to ensure that the data is correct once
the mesh is reassembled. The mass for each node is the sum of the
contributions from the neighboring volumetric elements. If the node is
a boundary node, these volumetric elements may be split across multiple
chunks so that the local boundary nodes in a given chunk receive
only a contribution from the local volumetric elements. The resulting
acceleration calculations, which rely on the nodal masses, would therefore
by incorrect for all the boundary nodes. The FEM framework is able to
account for this lack of data of shared nodes by combining the
data across all chunks. As a result, all chunk boundary calculations will
always be duplicated in each chunk but this added cost insures
that the solution will be accurate. The boundary nodes are all stored
in a field by calling
where fieldid is the ID of the current field.
datatype describes the type of the data which is shared, either
FEM_BYTE, FEM_INT, FEM_REAL, or FEM_DOUBLE.
The vectorlength describes the number of data items associated
with each node. For example, we store the node masses for each degree
of freedom where for 2-D systems is two - the resulting vector
length is . The offset is the byte offset form the start
of the node array to the actual data items to be shared. distance
is the byte offset from the first node to the second.
During the calculations within driver this field is updated
by calling
where fieldid specified the ID of the field defined during
the creation of the field. firstnode is the location of
the data array for the shared nodes.
Periodically, we may wish to output some current data for the
global mesh or even reassemble the mesh into its original form
so that we may change it and optionally repartition it again.
This can all be achieved by a call to the mesh_update routine
via
where callmeshupdated determines if the mesh_update routine
should be called immediately - when non-zero. Also, if dorepartition is
non-zero the mesh will be immediately reassembled on the first processor,
temporarily suspending the simulation, so that this mesh
can be modified or tested. The mesh is then repartitioned into several
chunks and redistributed to the processors. The chunks might
be different from the chunks defined at the start of the simulation.
On the other hand, if dorepartition is zero, the call is non-blocking which
allows the simulation to continue while mesh_update is called
because the only action allowed in this routine is limited to
the output of data.
Once the simulation is completed, for every chunk, the data is
reassembled on the first processor in the finalize
routine allowing the user to perform final calculations on the
serial mesh or simply output any necessary data to the screen
or files.
Next: Parallel Structure of the
Up: Parallel Implementation using Charm++
Previous: Computational Efficiency
Contents
Mariusz Zaczek
2002-10-13